
Language models might be able to self-correct biases—if you ask them
A study from AI lab Anthropic shows how simple natural-language instructions can steer large language models to produce less toxic content.

Articles by Niall Firth's Profile

Guillermo Preciado (@gpreciado62) / X

New dataset, metrics enable evaluation of bias in language models - Science

What to Know About AI Self-Correction
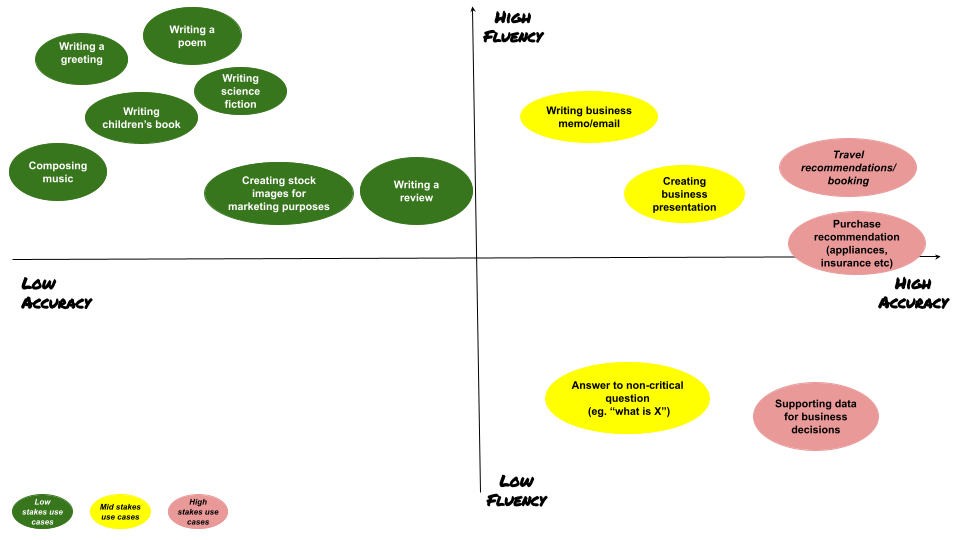
Framework for evaluating Generative AI use cases

Guillermo Preciado (@gpreciado62) / X

Articles by Antonio Regalado

Simon Porter on LinkedIn: Language models might be able to self

Large pre-trained language models contain human-like biases of what is right and wrong to do

Deciphering the data deluge: how large language models are transforming scientific data curation

Guillermo Preciado (@gpreciado62) / X

Georg Huettenegger on LinkedIn: Language models might be able to
The Full Story of Large Language Models and RLHF

Exploring Reinforcement Learning with Human Feedback









