
Spark Performance Optimization Series: #1. Skew
In Spark cluster data is typically read in as 128 MB partitions which ensures even distribution of data. However, as the data is transformed (e.g. aggregated), it is possible to have significantly…

Spark Job Optimization: Dealing with Data Skew
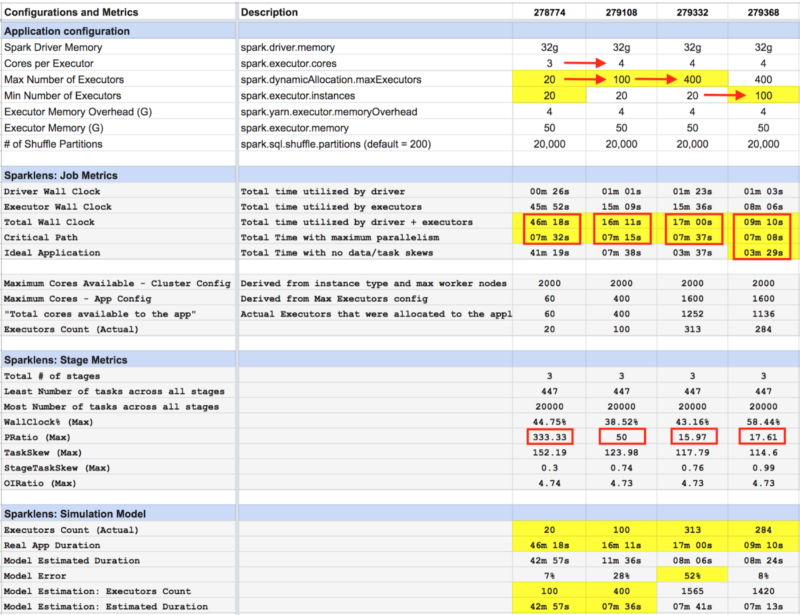
Spark Application Optimization for Performance using Qubole Sparklens

Spark Performance Optimization Series: #2. Spill, by Himansu Sekhar, road to data engineering

Spark Performance Optimization Series: #1. Skew, by Himansu Sekhar, road to data engineering

Spark Performance Tuning & Best Practices - Spark By {Examples}

Kubernetes Architecture,Hands On!, by Himansu Sekhar

Spark Performance Tuning: Skewness Part 1, by Wasurat Soontronchai
List of cool blogs focussing on Spark performance optimization., by Sukul Mahadik
Databricks Notebook Promotion using Azure DevOps, by Himansu Sekhar, road to data engineering

High Performance Spark: Best Practices for Scaling and Optimizing Apache Spark: Karau, Holden, Warren, Rachel: 9781491943205: : Books
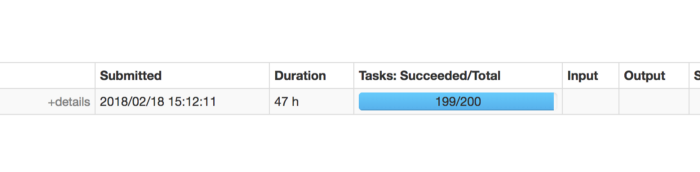
Optimizing the Skew in Spark

Spark's Data Skew Odyssey: Conquering the Chaos, by Bharathkumar V









