Fine tuning Meta's LLaMA 2 on Lambda GPU Cloud
This blog post provides instructions on how to fine tune LLaMA 2 models on Lambda Cloud using a $0.60/hr A10 GPU.
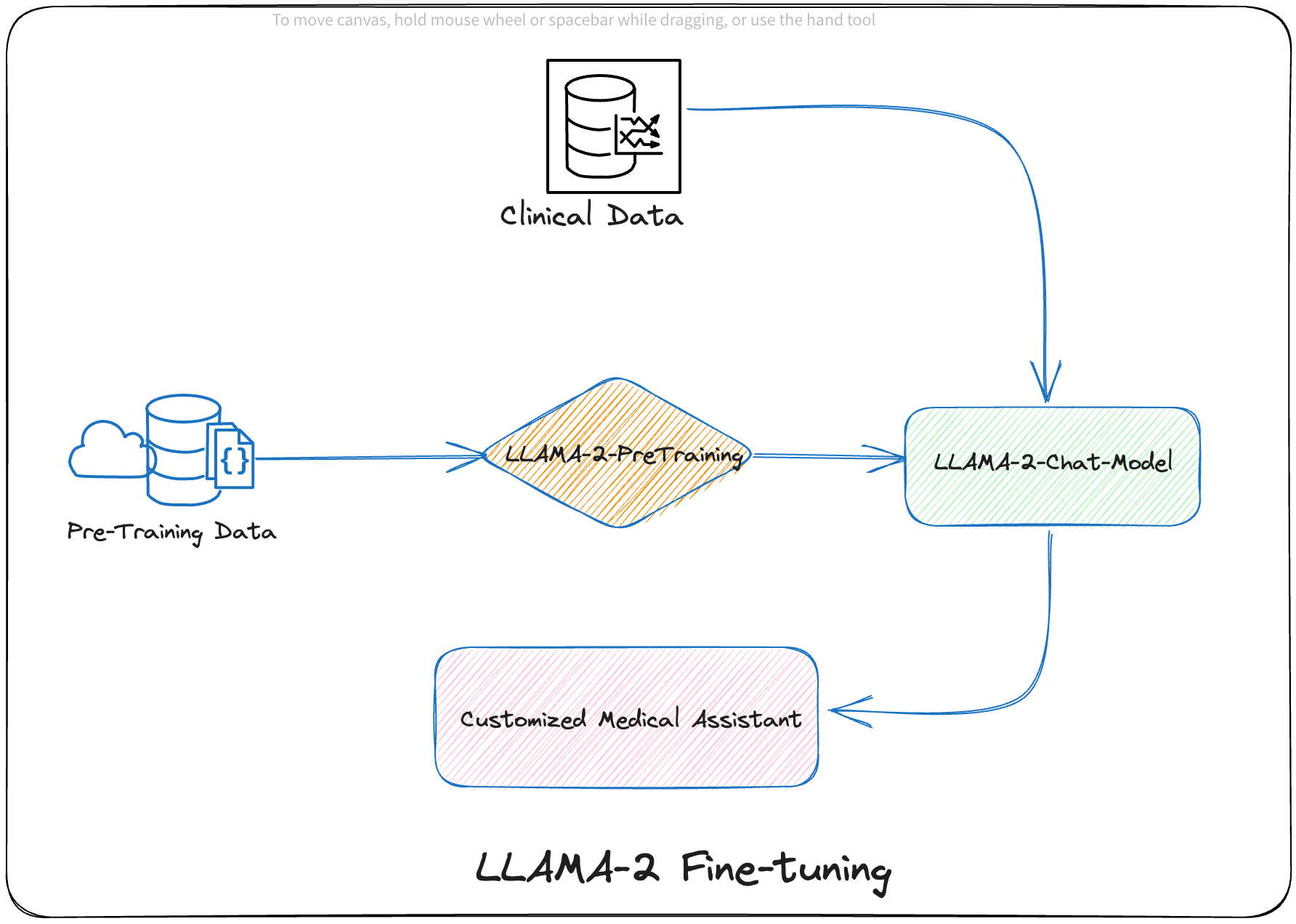
Building an AI Medical Assistant Part 1: LLama2 Fine-Tuning with Hugging Face Containers, QLoRA and PEFT With WANDB in AWS Sagemaker Spot Instances to cut LLM customization costs.”

Zongheng Yang on LinkedIn: Serving LLM 24x Faster On the Cloud with vLLM and SkyPilot

Fine-Tuning LLaMA 2 Models using a single GPU, QLoRA and AI Notebooks - OVHcloud Blog
How to Seamlessly Integrate Llama2 Models in Python Applications Using AWS Bedrock: A Comprehensive Guide, by Woyera

Fine-tune LLaMA 2 (7-70B) on SageMaker

A simple guide to fine-tuning Llama 2

Fine-tuning large language models in practice: LLaMA 2

Mitesh Agrawal on LinkedIn: GitHub - huggingface/community-events: Place where folks can contribute to…
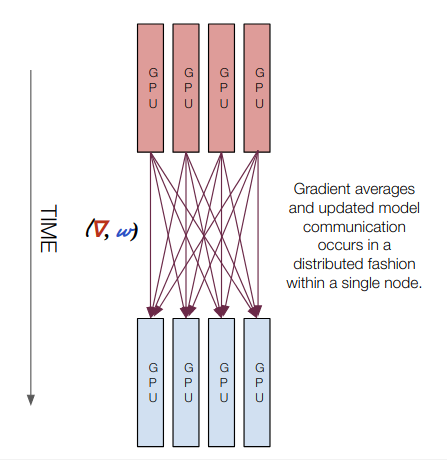
The Lambda Deep Learning Blog

Fine-Tuning LLaMA 2 Models using a single GPU, QLoRA and AI Notebooks - OVHcloud Blog
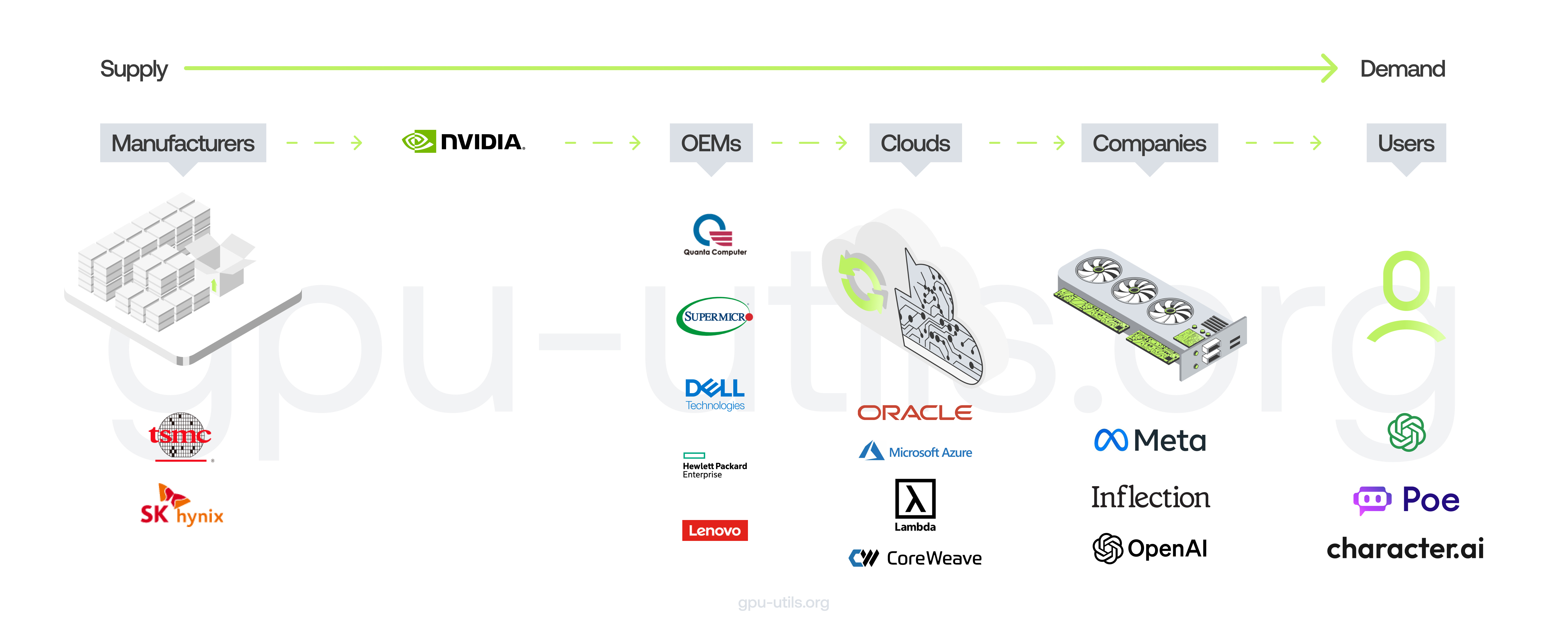
2023 Year in Review: The Great GPU Shortage and the GPU Rich/Poor
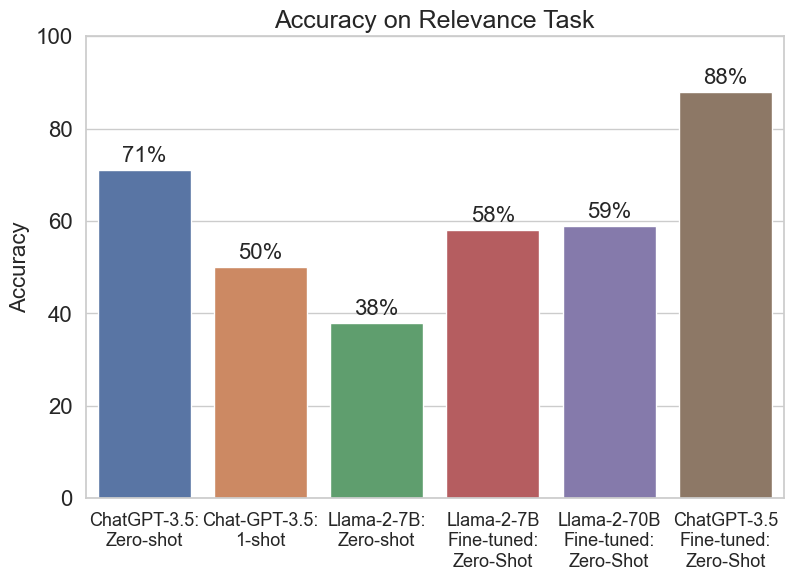
Devon Brackbill