DistributedDataParallel non-floating point dtype parameter with
🐛 Bug Using DistributedDataParallel on a model that has at-least one non-floating point dtype parameter with requires_grad=False with a WORLD_SIZE <= nGPUs/2 on the machine results in an error "Only Tensors of floating point dtype can re
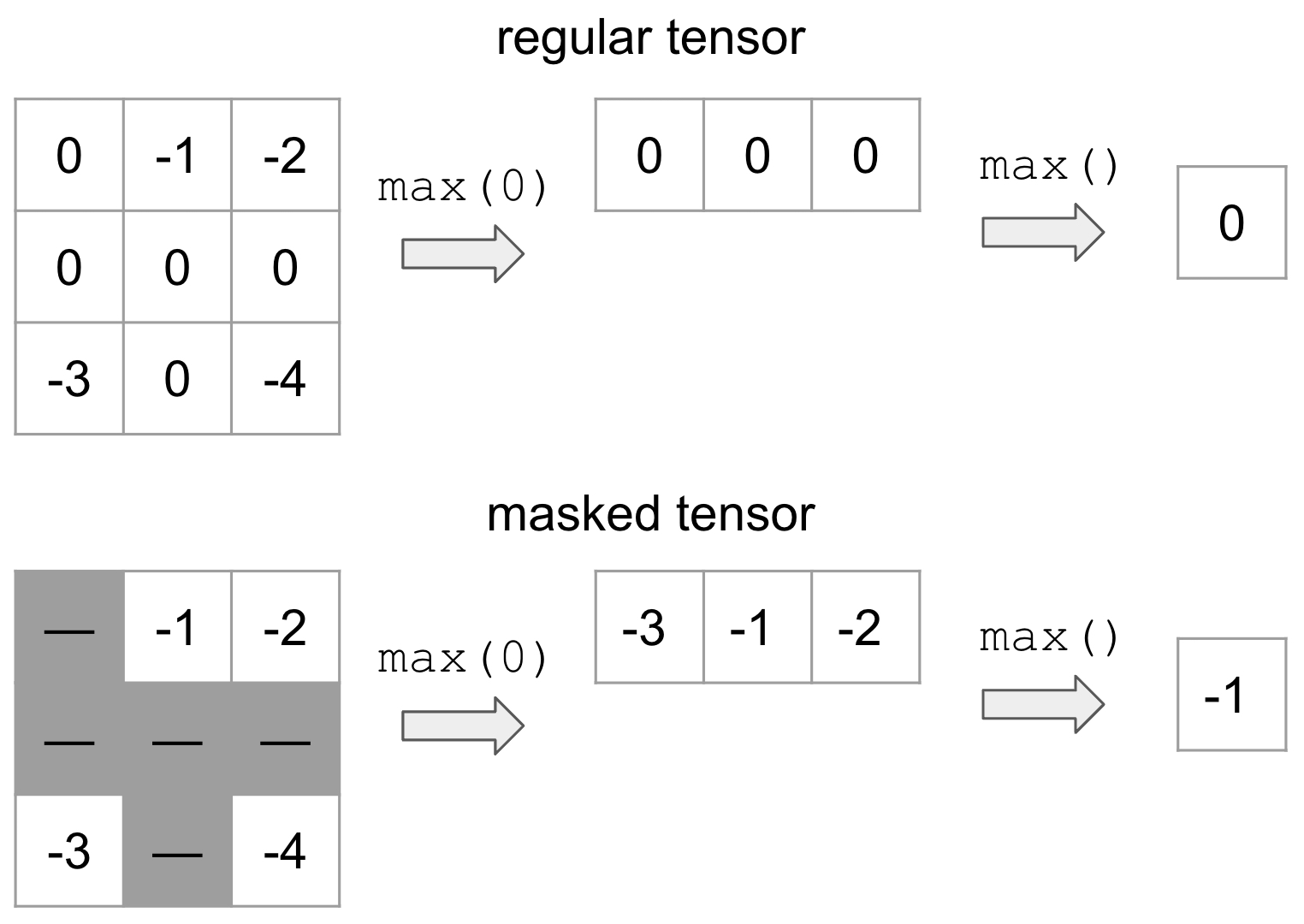
torch.masked — PyTorch 2.2 documentation
fairscale/fairscale/nn/data_parallel/sharded_ddp.py at main · facebookresearch/fairscale · GitHub

A comprehensive guide of Distributed Data Parallel (DDP), by François Porcher

PyTorch Numeric Suite Tutorial — PyTorch Tutorials 2.2.1+cu121 documentation
DistributedDataParallel non-floating point dtype parameter with requires_grad=False · Issue #32018 · pytorch/pytorch · GitHub

Configure Blocks with Fixed-Point Output - MATLAB & Simulink - MathWorks Nordic

Sharded Data Parallelism - SageMaker

Error Message RuntimeError: connect() timed out Displayed in Logs_ModelArts_Troubleshooting_Training Jobs_GPU Issues
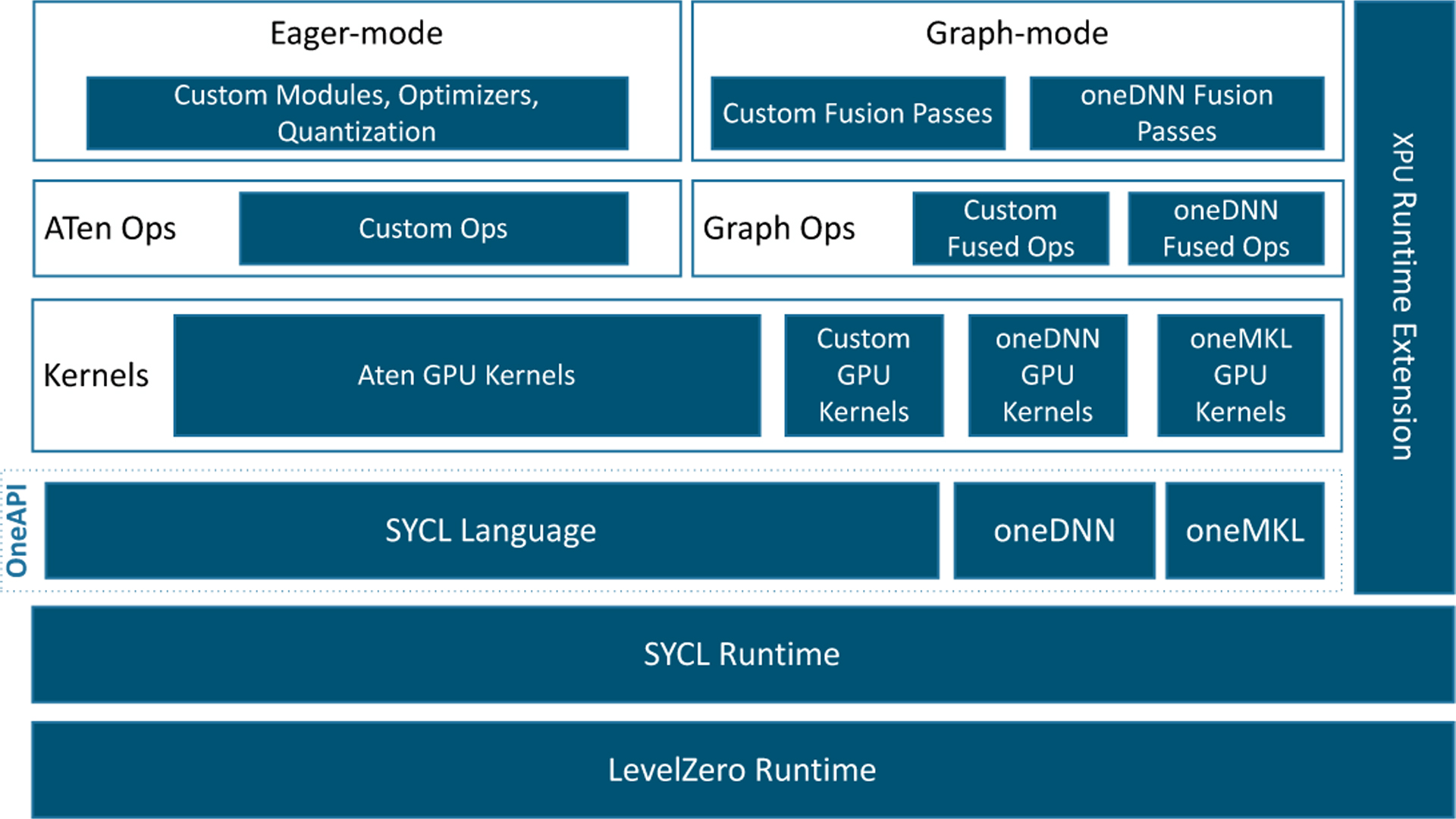
Introducing the Intel® Extension for PyTorch* for GPUs
How much GPU memory do I need for training neural nets using CUDA? - Quora
nll_loss doesn't support empty tensors on gpu · Issue #31472 · pytorch/pytorch · GitHub
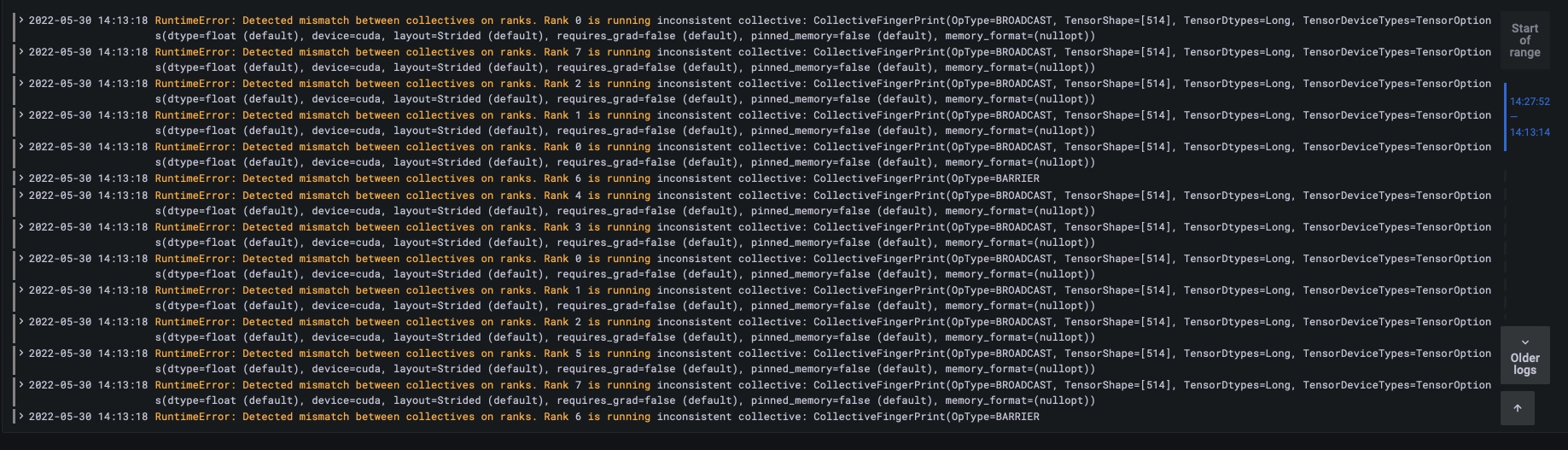
Detected mismatch between collectives on ranks - distributed - PyTorch Forums







